从 PDF 提取表格数据:4种简单到高级的方法
从 PDF 提取表格数据:4种简单到高级的方法
PDF 在保留文档布局方面表现出色,但从其中提取表格数据可能会令人沮丧。主要原因是 PDF 设计用于跨设备的一致视觉渲染,而不是用于结构化数据提取。因此,表格可能以可选中文本的形式存在于数字 PDF 中,或以图像形式存在于扫描文件中,其结构差异很大。
幸运的是,有几种实用的方法可以从 PDF 中提取表格数据 ,具体取决于你的需求和技术熟练程度。在本指南中,我们将介绍四种有效的方法,从简单的无代码工具(如 Excel 和 Google 文档)到基于 Python 的强大解决方案,以实现完全控制和自动化。
方法概述:
- 方法 1:Microsoft Excel(内置 PDF 导入功能)
- 方法 2:Google 文档(免费且简单)
- 方法 3:Adobe Acrobat Pro(导出功能)
- 方法 4:Python(完全控制与自动化)
方法 1:Microsoft Excel(内置 PDF 导入功能)
最适合: 拥有 Microsoft Office 365 或 Excel 2016+(仅限 Windows)的 Windows 用户。
Microsoft Excel 具有原生的 PDF 导入功能,对于可搜索 PDF 效果相当不错。它直接连接到文件并尝试检测和转换表格。
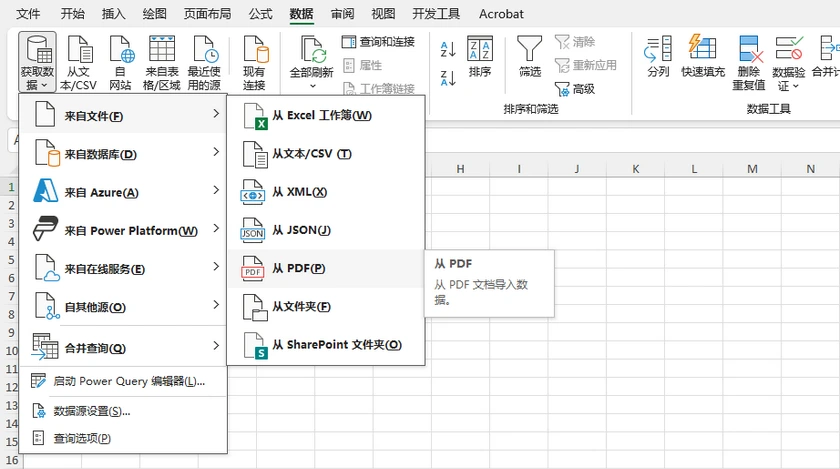
分步说明
- 打开 Microsoft Excel。
- 转到数据 → 获取数据 → 从文件 → 从 PDF 。
- 浏览并选择你的 PDF 文件。
- 将出现一个导航器窗口,显示所有检测到的表格和页面。
- 选择你想要的表格,然后点击加载(直接导入)或转换数据(在加载前进行清理)。
- Excel 会将表格导入到工作表中,相当好地保留了行/列结构。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 无需额外软件(使用 Office 时) | 仅限 Windows |
| 保留数字格式 | 难以处理合并单元格 |
| 适用于可搜索的 PDF | 对扫描的 PDF 无 OCR 功能 |
| 如果 PDF 更新,可以刷新数据 | 处理大型 PDF 时可能较慢 |
方法 2:Google 文档(免费且简单)
最适合: 当你没有 Excel 或付费工具时,进行快速、一次性的提取。
Google 文档提供了一种隐藏但免费的方法来从 PDF 中提取表格数据。它的工作原理是将整个 PDF 转换为可编辑的 Google 文档,其中表格变成基于文本的网格。
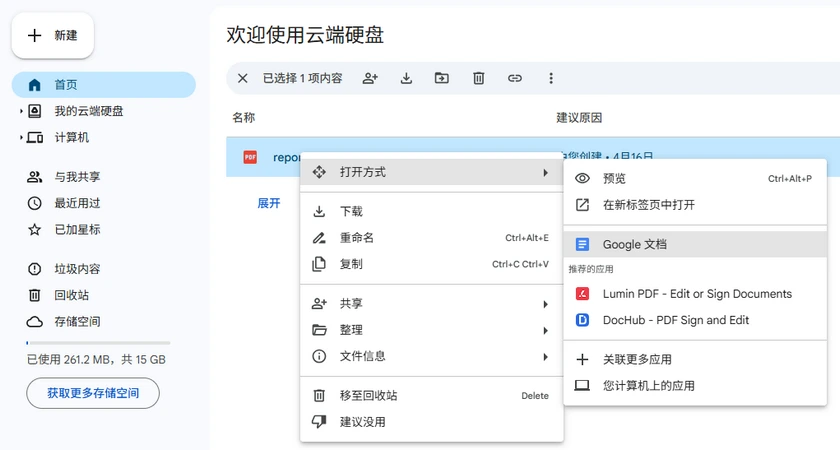
分步说明
- 将 PDF 上传到 Google Drive。
- 右键单击 PDF → 打开方式 → Google 文档 。
- 等待 Google Docs 处理文件。
- 滚动找到表格。它将显示为一个基于文本的网格(行和列由空格或制表符分隔)。
- 复制表格区域并将其粘贴到 Google Sheets 或 Microsoft Excel 中。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 完全免费 | 没有真正的表格检测(仅文本对齐) |
| 无需安装软件 | 复杂表格的结果混乱 |
| 可在任何装有浏览器的操作系统上使用 | 对合并单元格或多行单元格处理不佳 |
| 可靠地处理简单表格 | 无 OCR 功能(扫描的 PDF 显示为图像) |
方法 3:Adobe Acrobat Pro(导出功能)
最适合: 已经拥有 Acrobat Pro 并需要从可搜索 PDF 中可靠导出的专业人士。
Adobe Acrobat Pro(非免费 Reader)具有内置导出功能,可将 PDF 表格直接转换为 Excel 或 CSV。它比免费工具保留更多格式。
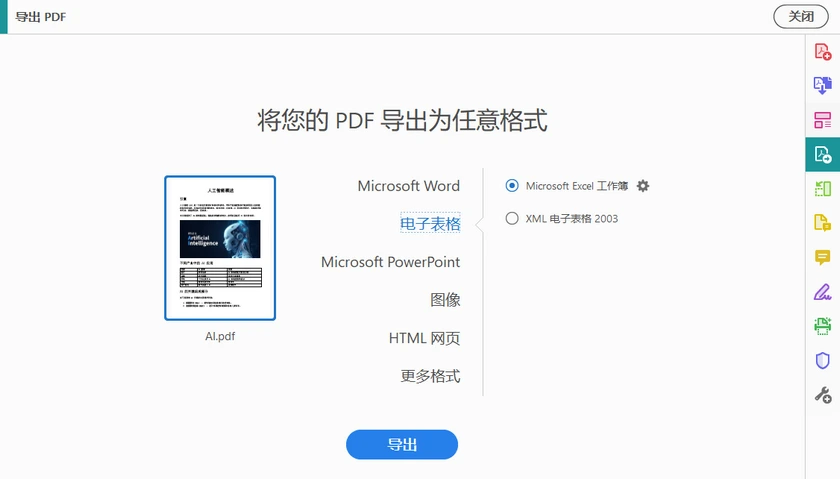
分步说明
- 在 Adobe Acrobat Pro 中打开 PDF。
- 点击导出 PDF(右侧工具栏)。
- 选择电子表格 → Microsoft Excel 工作簿(或 CSV) 。
- 点击导出。
- 选择一个位置并保存。
- 打开生成的 Excel 文件并验证表格。
附加提示
- 如果是处理扫描的 PDF,请先使用识别文本 (OCR) 选项。
- 对于多页表格,Acrobat 通常会智能地连接它们。
- 你可以仅导出选定的页面以节省时间。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 对可搜索 PDF 具有高准确性 | 昂贵(需要订阅) |
| 能很好地处理多页表格 | 对提取缺乏精细控制 |
| 保留公式和数字 | 仍然难以处理高度复杂的嵌套表格 |
| 支持批处理 | 仅限 Windows/macOS(无网页版) |
方法 4:Python(完全控制与自动化)
最适合: 需要最大灵活性、处理扫描 PDF 或批量处理文件的开发人员、数据科学家和高级用户。
Python 让你完全控制提取过程。你可以使用像 pdfplumber、camelot 或 Spire.PDF for Python(一个提供免费版本的商业库)这样的库来处理可搜索 PDF。下面是一个使用 Spire.PDF 提取表格数据并将其保存为干净的文本文件的实际示例。
安装
1 | pip install spire.pdf |
完整代码示例(将表格提取到 TXT 文件)
以下代码从特定 PDF 页面提取所有表格,并将每个表格保存为 CSV 格式的单独文本文件:
1 | from spire.pdf.common import * |
输出:
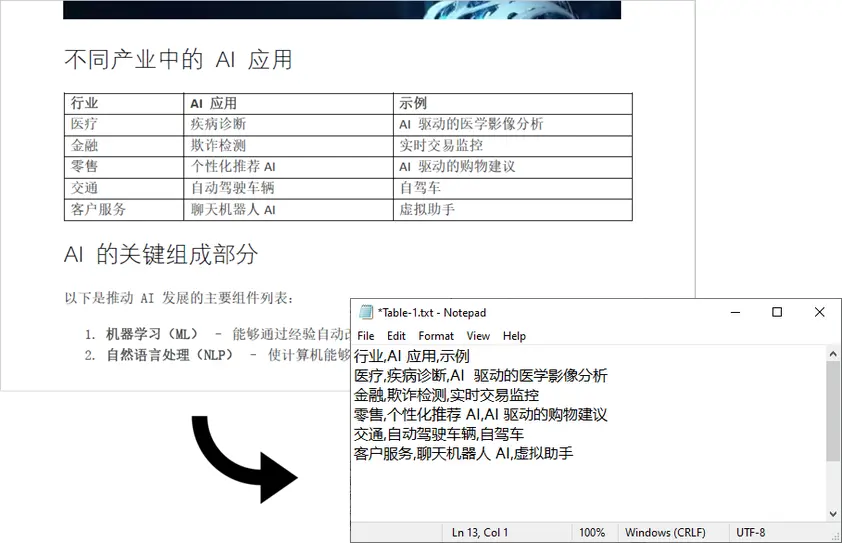
注意: 此脚本仅适用于可搜索的 PDF(基于文本)。对于扫描的 PDF,仅使用 Spire.PDF 是不够的。在这种情况下,你可以首先使用 Spire.PDF 将 PDF 转换为图像,然后应用像 pytesseract 这样的 OCR 引擎以及额外的处理逻辑来检测和提取表格数据。
为什么选择 Python?
- 处理可搜索和扫描的 PDF(需结合 OCR)
- 批量处理数百个文件
- 可自定义的后处理(清理、合并、验证)
- 可以集成到 Web 应用、API 或 ETL 管道中
- 你完全可以控制表格的格式化和保存方式
作为一个全面的 PDF 库,Spire.PDF for Python 不仅可以从 PDF 中提取表格数据,还支持提取图片、元数据和附件。此外,它还可以将整个文档导出为 Word、Excel 和 TXT 等格式。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 完全控制提取逻辑 | 需要编程知识 |
| 处理复杂和多页表格 | 学习曲线较陡峭 |
| 批量处理数千个文件 | Spire.PDF 需要商业使用许可证(个人使用免费) |
| 干净、可重复的结果 | 并非在所有 PDF 上的表格检测都是完美的 |
| 易于与 pandas、Excel 或数据库集成 |
对比表:选择合适的方法
| 方法 | 易用性 | 处理扫描的 PDF | 批处理 | 成本 | 最适合 |
|---|---|---|---|---|---|
| Excel | 中等 | x | x | 需要 Office | 快速、一次性的数字表格 |
| Google 文档 | 高 | x | x | 免费 | 简单的表格,无需软件 |
| Adobe Acrobat Pro | 高 | √ | √ | 付费 | 专业的、非技术用户 |
| Python | 低 | √ | √ | 免费/付费 | 最大灵活性、大规模、扫描的 PDF |
结论
从 PDF 中提取表格数据不必是件头疼的事。正确的方法完全取决于你的具体情况:
- 对于一次性的简单表格 → 首先尝试 Google Docs 或在线工具。
- 为了专业、完善的结果 → 如果你有权限,使用 Excel 或 Adobe Acrobat Pro。
- 为了最大控制权、复杂表格或扫描文档 → Python 是你最好的选择。
从满足你需求的最简单方法开始。随着你的要求增长(更多文件、扫描文档、自定义清理),你总是可以升级到更强大的工具,如 Python。关键是要认识到表格提取不是一个一刀切的问题——而现在你有四种方法来解决它。
常见问题解答
问题 1. 为什么从 PDF 中提取表格很难?
因为 PDF 将内容存储为定位文本而不是结构化数据表格,使得提取不那么直接。
问题 2. 哪种方法给出的结果最准确?
对于复杂表格,Adobe Acrobat Pro 通常提供最佳准确性。
问题 3. 我可以从扫描的 PDF 中提取表格吗?
可以,但这需要 OCR(光学字符识别)。您可以使用 Spire.PDF 将 PDF 转换为图片,然后使用 Spire.OCR 提取图片上文本(包括表格)。
问题 4. Python 比其他方法更好吗?
这要看情况。Python 最适合自动化和大规模处理,但对于一次性任务来说则有些大材小用。
问题 5. 我可以直接将提取的表格转换为 Excel 吗?
可以。大多数工具(Excel、Acrobat)支持直接导出为 .xlsx 格式,而 Python 可以扩展以实现同样的功能。










